二十五岁时我们都一样愚蠢、多愁善感,喜欢故弄玄虚,可如果不那样的话,五十岁时也就不会如此明智。


标题:Python并发与并行
并发和并行都用于多线程程序,但是它们之间的相似性和差异存在很多混淆。这方面的一个重要问题是:并发并行性与否?尽管这两个术语看起来非常相似,但上述问题的答案是否定的,但并发性和并行性并不相同。现在,如果它们不相同,那么它们之间的基本区别是什么?
简单来说,并发性涉及管理来自不同线程的共享状态访问,另一方面,并行性涉及利用多个CPU或其核心来提高硬件性能。
并发细节
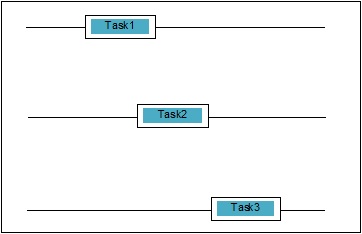
并发是指两个任务在执行时重叠。可能是应用程序同时在多个任务上进行的情况。我们可以用图解理解它; 多项任务正在同时取得进展,具体如下 -
并发级别
在本节中,我们将从编程方面讨论三个重要的并发级别 -
低级并发
在这种并发级别中,明确使用原子操作。我们不能在应用程序构建中使用这种并发性,因为它非常容易出错且难以调试。甚至Python也不支持这种并发。
中级并发
在这种并发中,没有使用显式原子操作。它使用显式锁。Python和其他编程语言支持这种并发。大多数应用程序员使用这种并发性。
高级并发
在这种并发中,既不使用显式原子操作也不使用显式锁。Python有 concurrent.futures 模块来支持这种并发。
并发系统的属性
要使程序或并发系统正确,必须满足某些属性。与终止系统有关的属性如下 -
正确的财产
正确性属性意味着程序或系统必须提供所需的正确答案。为了简单起见,我们可以说系统必须正确地将起始程序状态映射到最终状态。
安全财产
安全属性意味着程序或系统必须保持 “良好” 或 “安全” 状态,并且永远不会做任何 “坏事” 。
生活财产
此属性意味着程序或系统必须 “取得进展” 并且它将达到某种理想状态。
并发系统的参与者
这是并发系统的一个常见属性,其中可以有多个进程和线程,它们同时运行以在自己的任务上取得进展。这些进程和线程称为并发系统的actor。
并发系统的资源
演员必须利用内存,磁盘,打印机等资源才能执行任务。
某些规则
每个并发系统必须拥有一套规则来定义演员要执行的任务类型以及每个系统的时间安排。任务可能是获取锁,内存共享,修改状态等。
并发系统的障碍
在实现并发系统时,程序员必须考虑以下两个重要问题,这些问题可能是并发系统的障碍 -
共享数据
实现并发系统时的一个重要问题是在多个线程或进程之间共享数据。实际上,程序员必须确保锁保护共享数据,以便对其进行所有访问,并且一次只有一个线程或进程可以访问共享数据。如果多个线程或进程都试图访问相同的共享数据,那么除了其中至少一个之外的所有线程或进程都不会被阻止并且将保持空闲状态。换句话说,我们可以说当锁定生效时我们只能使用一个进程或线程。可以有一些简单的解决方案来消除上述障碍
数据共享限制
最简单的解决方案是不共享任何可变数据。在这种情况下,我们不需要使用显式锁定,并且可以解决由于相互数据导致的并发障碍。
数据结构协助
很多时候并发进程需要同时访问相同的数据。除了使用显式锁之外,另一种解决方案是使用支持并发访问的数据结构。例如,我们可以使用 队列 模块,它提供线程安全的队列。我们还可以使用 multiprocessing.JoinableQueue 类来实现基于多处理的并发。
不可变数据传输
有时,我们使用的数据结构,比如并发队列,不适合我们可以传递不可变数据而不锁定它。
可变数据传输
继续上述解决方案,假设是否只需要传递可变数据而不是不可变数据,那么我们就可以传递只读的可变数据。
共享I / O资源
实现并发系统的另一个重要问题是线程或进程使用I / O资源。当一个线程或进程使用I / O这么长时间而其他线程或进程空闲时,就会出现问题。在处理I / O繁重的应用程序时,我们可以看到这种障碍。在示例的帮助下可以理解从Web浏览器请求页面。这是一个繁重的应用程序。在这里,如果请求数据的速率低于它的消耗速率,那么我们的并发系统中就有I / O障碍。
以下Python脚本用于请求网页并获取我们的网络获取所请求页面所花费的时间
import urllib.request import time ts = time.time() req = urllib.request.urlopen('http://www.codingdict.com') pageHtml = req.read() te = time.time() print("Page Fetching Time : {} Seconds".format (te-ts))执行上述脚本后,我们可以获取页面获取时间,如下所示。
产量
Page Fetching Time: 1.0991398811340332 Seconds我们可以看到获取页面的时间超过一秒。现在,如果我们想要获取数千个不同的网页,您可以了解我们的网络将花费多少时间。
什么是Parallelism?
并行性可以定义为将任务分成可以同时处理的子任务的技术。如上所述,它与并发性相反,其中两个或多个事件同时发生。我们可以用图解理解它; 任务分为若干可以并行处理的子任务,如下所示 -
要更多地了解并发性和并行性之间的区别,请考虑以下几点 -
并发但不平行
应用程序可以是并发但不是并行意味着它同时处理多个任务,但任务不会分解为子任务。
并行但不并发
应用程序可以是并行但不是并发意味着它一次只能在一个任务上运行,并且可以并行处理分解为子任务的任务。
无论是并行还是并发
应用程序既不能并行也不能并发。这意味着它一次只能处理一个任务,并且任务永远不会分解为子任务。
并行和并发
应用程序可以是并行和并发意味着它既可以一次处理多个任务,也可以将任务分解为子任务以并行执行它们。
并行性的必要性
我们可以通过在单个CPU的不同核心之间或在网络内连接的多个计算机之间分配子任务来实现并行性。
考虑以下要点,以了解为什么有必要实现并行性 -
高效的代码执行
借助并行性,我们可以有效地运行代码。它将节省我们的时间,因为部分中的相同代码并行运行。
比顺序计算更快
顺序计算受物理和实际因素的限制,因此不可能获得更快的计算结果。另一方面,这个问题通过并行计算解决,并且比顺序计算给我们更快的计算结果。
减少执行时间
并行处理减少了程序代码的执行时间。
如果我们谈论并行性的真实例子,我们计算机的显卡就是突出并行处理真正力量的例子,因为它拥有数百个独立工作的独立处理内核,可以同时执行。由于这个原因,我们也能够运行高端应用程序和游戏。
了解处理器的实现
我们知道并发性,并行性和它们之间的区别,但是它实现的系统又如何呢?理解我们将要实施的系统是非常必要的,因为它为我们提供了在设计软件时做出明智决策的好处。我们有以下两种处理器
单核处理器
单核处理器能够在任何给定时间执行一个线程。这些处理器使用 上下文切换 在特定时间存储线程的所有必要信息,然后再恢复信息。上下文切换机制可以帮助我们在给定秒内的多个线程上取得进展,看起来好像系统正在处理多个事情。
单核处理器具有许多优点。这些处理器需要更少的功率,并且多个核之间没有复杂的通信协议。另一方面,单核处理器的速度有限,不适合大型应用。
多核处理器
多核处理器具有多个独立的处理单元,也称为 核心 。
这样的处理器不需要上下文切换机制,因为每个核包含执行一系列存储指令所需的一切。
获取 - 解码 - 执行周期
多核处理器的核心遵循一个执行周期。该循环称为 Fetch-Decode-Execute 循环。它涉及以下步骤 -
取
这是循环的第一步,它涉及从程序存储器中取出指令。
解码
最近获取的指令将被转换为一系列信号,这些信号将触发CPU的其他部分。
执行
这是执行读取和解码指令的最后一步。执行结果将存储在CPU寄存器中。
这里的一个优点是多核处理器中的执行速度比单核处理器的执行速度快。它适用于大型应用。另一方面,多核之间的复杂通信协议是一个问题。多核需要比单核处理器更多的功率。